
Bigtable — System Architecture
How Google’s Bigtable stores and scales structured data: master for coordination, tablet servers for data, all built on GFS and Chubby.
1. Tablet Location
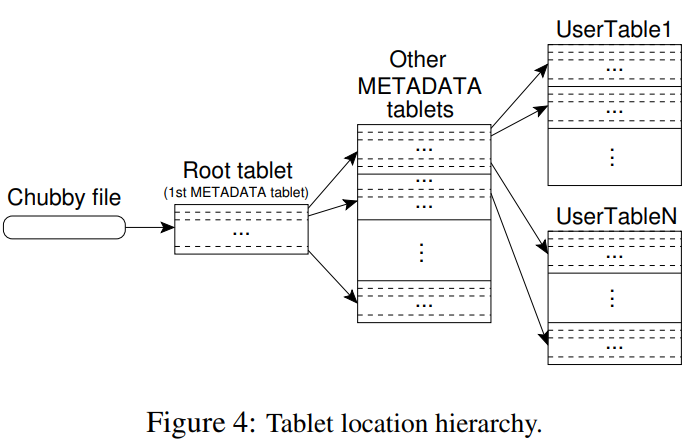
Clients find tablets via a three-level index: Chubby → Root tablet → Metadata tablets → User tablets. Tablet servers hold leases; the master reassigns tablets when needed.
2. Serving Data
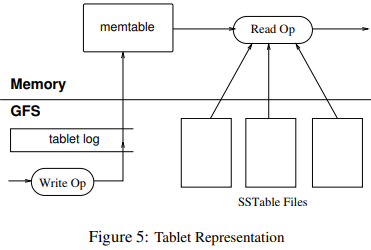
Each tablet stores data as an in-memory memtable and a set of SSTables on disk. Updates are written to a commit log and then applied to the memtable.
Reads: Merge memtable and SSTables using Bloom filters and caches.
3. Compactions & Optimization
Compactions merge SSTables to limit file count and improve performance. Bloom filters skip files that can’t contain requested rows.
- Locality groups group columns read together
- Compression saves space with minimal CPU cost
4. Recovery
Each tablet server writes a shared log for all tablets. On restart, it replays the log to rebuild memtables. SSTables are immutable, simplifying concurrency and garbage collection.
5. Summary
- Architecture: Master + Tablet Servers + GFS
- Data path: Log → Memtable → SSTables
- Speed: Caches + Bloom filters + Compaction
- Scalability: Horizontal growth and simple control